This post is all about KAFKA! By the end of this post you should have idea about its design philosophy, components, and architecture.
Kafka is written in Scala and doesn't follow JMS standards.
What is Apache Kafka ?
Kafka is a distributed streaming platform which is highly scalable, fault-tolerant and efficient (provides high throughput and low latency). Just like other messaging platforms it allows you to publish and subscribe stream of records/messages..but as a platform it offer much more. An important distinction worth mentioning is -it's NOT a Queue implementation but it can be used as Queue. It can be used to pipe data flow between two systems something which has traditionally been done through ETL systems.
What is Stream Processing ?
Let's understand what is stream processing before we delve deeper. Jay Kreps, who implemented Kafka along with other members while working at LinkedIn explains about stream processing, here. Let's cover programming paradigms -
- Request/Response- Send ONE request and wait for ONE response (a typical http or REST call).
- Batch- Send ALL inputs, batch job does data crunching/processing and then returns ALL output in one go.
- Stream Processing- Program has control in this model, it takes (bunch of) inputs and produces SOME output. SOME here depends on the program - it can return ALL output or ONE or it can do everything in-between. So, this is basically generalisation of above two extreme models.
Stream processing is generally async. Stream processing has also been popularised by Lambdas and frameworks like Rx - where stream processing is confined to a process. But, in case of Kafka- stream processing is distributed and really large!
What is Event Stream ?
Events are actions which generate data!
Databases store the current state of data, which has been reached by sequence or stream of events. Visualising data as stream of events might not be very obvious, especially if you have grown seeing data being stored as rows in databases.
Let's take example of your bank balance - your current bank balance is result of all credit and debit events which have occurred in the past. Events are business story which resulted in the current state of data. Similarly, current price of a stock is due to all the buy and sell events which have happened from the day it got listed on a bourses; in retail domain data can be realised as- stream of orders, sells and price adjustments. Google earns billions of dollers by capturing click events and impression events.
Now companies want to records all user events on their sites - this helps in better profiling the customers and offering more customised services. This has led to tons of data being generated. So, when we hear about the term big data - it basically means capturing all these events which most of the companies were ignoring earlier.
Kafka's Core Data Structure
There are quite similarities between stream of records and application logs. Both order the entries with time. At the core, Kafka uses something similar to record all the stream of events - Commit Log. I have discussed separately about commit logs, here.
Kafka provides commit log of updates as shown in below image. Data Sources ( or Producers) can publish stream of events or records which gets stored in commit log and then subscribers or consumers (like DB, Cache, http service) can read those events. These consumers are independent of each other and have their own reference points to read records.
 |
| https://www.confluent.io/blog/stream-data-platform-1/ |
Commit logs can be partitioned or shared across cluster of nodes and they are also replicated to achieve fault-tolerance.
How Kafka storage internally works: https://thehoard.blog/how-kafkas-storage-internals-work-3a29b02e026
Key Concepts and Terminologies
Let's cover important components and aspects of Kafka:
Message
Message is record or information which gets persisted in Kafka for processing. It's a fundamental unit of data in Kafka world. Kafka stores the message in binary format.
Topics
Messages in Kafka are categorised under topic. Topic is like a database table. Messages are always published and subscribed from a given topic (name). For each topic, Kafka maintains a structured commit log with one or more partitions.
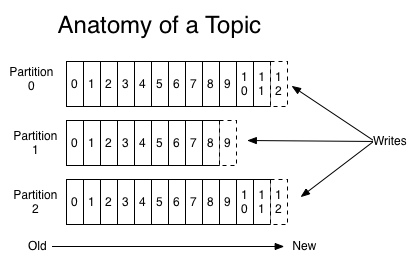
Partition
A topic can have multiple partition as shown in above figure. Kafka appends new message at the end of a partition. Each message in a topic is assigned a unique identifier known as offset. Write to a partition are sequential (from left to write) but write across different partitions can be done in parallel as each partition may be in a different box/node. Offset uniquely identifies a message in a given partition. Current offset where message is going to be written in partition 0 is 12 (in above pic).
Ordering of record is guaranteed only across a partition of the given topic. Partition allows Kafka to go beyond the limitation of a single server. This means single topic can be scalled horizontally across multiple servers. But at the same time each individual partition must fit in a host.
Each partition has one server which acts as leader and zero or more servers which acts as follower. The leader handles all reads and writes requests for that partition and follower replicate. If the leader fails, one of the follower will get chosen as leader. Each server acts a leader for some partition and follower for others so that load is balanced.
Producers
As the name suggests, Producers post messages to topics. Producer is responsible for assigning messages to a partition in a given topic. Producer connects to any of the alive nodes and requests metadata about the leaders for the partition of a topic. This allows the producer to put the message directly to the lead broker of the partition.
Consumers
Consumers subscribe to one or more topics and read messages for further processing. It's consumers job to keep track of which message have been read using offset. Consumers can re-read past messages or can jump to future messages as well. This is possible because Kafka retains all messages for a given time (which is pre configured).
Consumer Group
Kafka scales the consumption by grouping consumers and distributing partitions among them.
 |
| https://cdn2.hubspot.net/hubfs/540072/New_Consumer_figure_1.png |
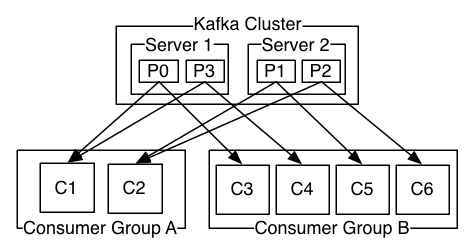
Above diagram shows a topic with 3 partitions and a consumer group with 2 members. Each partition of topic is assigned to only one member in the group. Group coordination protocol is built into Kafka itself (earlier it was managed through zookeeper). For each group one broker is selected as group co-ordinator. It's main job is to control partition assignment when there is any change (addition/deletion) in membership of the group.
 |
| https://kafka.apache.org/0110/images/consumer-groups.png |
- If all consumer instances have same consumer group, then records will get load balanced over consumer instances.
- If all the consumer instances have different consumer groups, then each record will be broadcast to all consumer processes.
Brokers
Kafka is a distributed system, so topics could be spread across different nodes in a cluster. These individual nodes or servers are known as brokers. Brokers job is to manage persistence and replication of messages. Brokers scale well as they are not responsible for tracking offset or messages for individual consumers. Also there is no issue due to rate with which consumer consumes messages. A single broker can easily handle thousands of partitions and millions of messages.
Within a cluster of brokers, one will be elected as cluster controller. This happens automatically among live brokers.
A partition is owned by a single broker of the cluster and that broker acts as partition leader. To achieve replication, a partition will be assigned to multiple brokers. This provides redundancy of the portion and will be used as leader if the primary one fails.
Leader
Node or Broker responsible for all the reads and writes of the given partition.
Replication Factor
Replication factor controls the number of replica copies. If a topic is un-replicated then replication factor will be 1.
If you want to design in such a way that f failures is fine then need to have 2f+1 replica.
So, for 1 node failure; replication factor should be set to 3.
Architecture
Below diagram shows all important components of Kafka and their relationship-

Role of Zookeeper
Zookeeper is an open source, high performance coordination service for distributed applications. In distributed systems Zookeeper helps in configuration management, consensus building, coordination and locks (Hadoop also uses Zookeeper). It acts as middle man among all nodes and helps in different co-ordination activities - it's source of truth.
In Kafka, it's mainly used to track status of cluster nodes and also to keep track of topics, partitions, messages etc. So, before starting Kafka server, you should start Zookeeper.
Kafka Vs Messaging Systems
Role of Zookeeper
Zookeeper is an open source, high performance coordination service for distributed applications. In distributed systems Zookeeper helps in configuration management, consensus building, coordination and locks (Hadoop also uses Zookeeper). It acts as middle man among all nodes and helps in different co-ordination activities - it's source of truth.
In Kafka, it's mainly used to track status of cluster nodes and also to keep track of topics, partitions, messages etc. So, before starting Kafka server, you should start Zookeeper.
Kafka Vs Messaging Systems
Kafka can be used as a traditional messaging systems (or Brokers) like ActiveMQ, RabitMQ, Tibco. Traditional messaging systems have two models - queuing and publish-subscribe. Each of these models have their own strengths and weaknesses -
Queuing- In this model pool of consumers can read from server and each record goes to one of them. This allows to divide up the processing over multiple consumers and helps in scale processing. But, queues are not multi-subscriber- once one subscriber reads data it's gone.
Publish-Subscribe- This model allows to broadcast data to multiple subscribers. But, this approach doesn't scale up as every message goes to every consumer/subscriber.
Kafka uses Consumer Group model; so every topic has both these properties (queue and publish-subscribe). It can scale processing and it's also multi-subscriber. Consumer group allows to divide up processing over different consumers of the group (just like queue model). And just like traditional pub-sub model it allows you to broadcast messages to multiple consumer groups.
Order is not guaranteed in tradition systems, if records needs to be delivered to consumers asynchronously they may reach to consumers out of order. Kafka does better by creating multiple partitions for the same topics and each partition is consumed by exactly one consumer in the group.
Kafka can be used as a traditional messaging systems (or Brokers) like ActiveMQ, RabitMQ, Tibco. Traditional messaging systems have two models - queuing and publish-subscribe. Each of these models have their own strengths and weaknesses -
Order is not guaranteed in tradition systems, if records needs to be delivered to consumers asynchronously they may reach to consumers out of order. Kafka does better by creating multiple partitions for the same topics and each partition is consumed by exactly one consumer in the group.
CLI Commands
CLI Commands
Here, goes a link which covers Kafka CLI commands.
-------
References:
"Write to a partition are sequential (from left to write) but write across different partitions can be done in parallel as each partition may be in a different box/node."
ReplyDeleteSomething is wrong in above statement. :)
Thanks for your comments Ramakant. Not sure what's problem in above statement, though.
DeleteCan you pls help me to understand what's wrong ? Thanks.